Companies in the digital economy collect more and more data every day. There are different data types with different meanings, which must be handled differently. Often, however, there is confusion, so we want to clarify the difference between first party, second party and third party data.
The difference between first, second and third party data
First party data is data that the company itself collects. For example, a company collects data like the email address, as well as the name and gender of the users, as part of the email marketing opt-in process. The company has access to the respective data set at any time and can use the data as approved by the user. Direct control and the independence from third parties are the main advantages of first party data. There are different ways to collect user data. 70 percent of companies generate such data via their own website (Econsultancy).
In order to enrich and extend their own data, a company sometimes has to resort to data that it has not collected by itself. Therefore, companies often integrate data from other companies or organizations, e.g. of market researchers. This form of data is called second and third party data. However, a company has to pay caution when using the data. There is always a dependency on the provider of this data. Are the data correct? Can I rely on the fact that the provider will not modify its terms and conditions any time soon and prohibit certain types of data usage? Can I use the data legally safe? This applies in particular to personal data, e.g. address data in email marketing. In case of doubt, the liability here is not with the provider, but with the user of the data.
Second party data refers to data obtained from another provider. It can be either a one-time purchase or a lasting partnership in which the partners exchange data.
For example, company A would like to buy data set X from company B. For company B, the data set X is first party data, since they collected the data by themselves. For enterprise A, the data set X becomes second party data, since A did not generate the data, but only company B. Company A is thus the “second party”. In general such an exchange or purchase is usually not a problem when it comes to anonymous market research data. In the case of personal data, the case is different since it is usually not possible to assume sufficient opt-ins to use this data.
If a company buys data, it can always lead to dependencies or complications with the other company, so trustworthy partnerships are even more important.
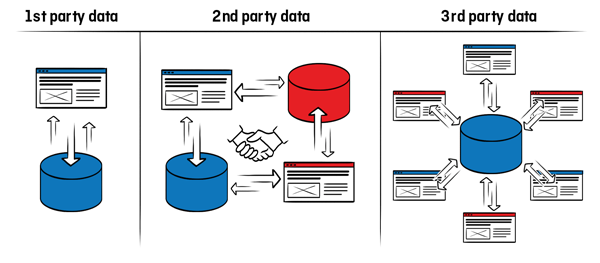
First, Second and Third Party Data (Source: Clearcode)
Third party data – helpful but at what price?
If a company needs very specific records or a large amount of particular data, it may be helpful to access third party data. Companies can purchase this kind of data from external sources, which have also acquired the data or collected it themselves. The business model of these external service providers is to collect, aggregate, and sell data from different sources. A great advantage of third party data is the fast availability and the large amount of available data. Negative is not only the cost. In addition, the use of this data is often questionable and risky, not only in terms of quality, but in terms of privacy regulations. For this reason, it is necessary to keep in mind the usage rights.