Zu den wesentlichen Aufgaben der Datenanalyse gehört die Erkennung von Mustern in den vorliegenden Daten. Z. B. ließe sich, wenn diese Daten vorliegen, analysieren, ob die Vorliebe für ein bestimmtes Produkt mit gewissen soziodemografischen Daten korreliert (Alter, Geschlecht, Wohnort etc.). Dies ist eine wichtige Erkenntnis für Marketer, die Produkte vermarkten möchten, für die es wichtig ist, die korrelierenden Datensätze mit den relevanten soziodemografischen Daten zu kennen, nicht jedoch die Personen hinter den Datensätzen identifizieren zu können.
Die Methode der Wahl bestünde hier in Pseudonymisierung oder ggf. sogar Anonymisierung. Selbst bei Pseudonymisierung besteht jedoch ein Restrisiko, dass einzelne Datensätze durch den Abgleich mit anderen Datenbeständen, die einen personenbezogenen Identifikator enthalten, doch wieder durch einen Unbefugten einer bestimmten Person zuzuordnen sind. Ein Beispiel zur Veranschaulichung: Im Rahmen einer Analyse von pseudonymisierten Daten findet ein Kampagnenmanager heraus, dass sich aus seinem Datenbestand drei männliche Personen im Alter von 20-30 Jahren in einer bestimmten Wohngegend mit bestimmten Hobbies für ein Produkt A interessieren. Aus öffentlich zugänglichen Daten ist ersichtlich, dass in dieser Gegend nur fünf männliche Personen in dieser Altersgruppe wohnen und wer diese Personen sind. Da diese Personen in Social Media und sonstigen Webauftritten über ihre Hobbies berichten, lässt sich durch etwas Recherche herausfinden, zu welchen dieser fünf Personen die drei untersuchten Datensätze höchstwahrscheinlich gehören.
Wie das Beispiel bereits zeigt, ist das Risiko der Aufhebung einer Pseudonymisierung für die meisten Anwendungsfälle relativ gering und mit viel Aufwand verbunden, es besteht aber grundsätzlich. Differential Privacy ist eine Methode, die eine solche Auflösung der Pseudonymisierung noch weiter erschwert. Die Methode erlaubt es, Erkenntnisse aus einem gesamten Datenbestand zu ziehen, ohne dabei einzelne Nutzer identifizierbar zu machen. Differential Privacy wird beispielsweise von Apple zur anonymisierten Auswertung von iOS-Nutzerdaten verwendet.
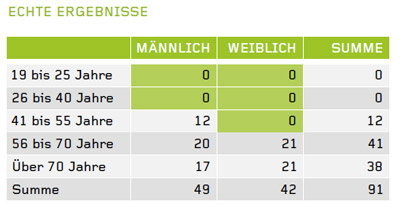
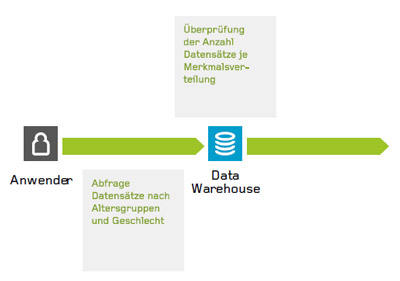
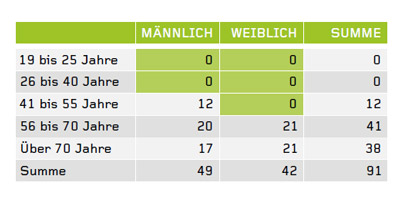
Was Differential Privacy genau beinhaltet, wird sehr unterschiedlich definiert, es haben sich aber zwei wesentliche Verfahren herauskristallisiert: Minimale Größe der Abfragemenge: Je weniger Datensätze mit bestimmten Merkmalskombinationen untersucht werden, desto größer ist das Risiko, diese konkreten Nutzern zuordnen zu können. Wenn sich in oben beschriebenem Beispiel 300 anstatt drei Personen im untersuchten Datenbestand befunden hätten, wäre die Zuordnung viel schwieriger, vielleicht sogar unmöglich. Die Lösung liegt darin, Minimalgrößen bei der Abfragemenge zu definieren. Im dargestellten Diagramm startet ein Anwender, z. B. ein Kampagnenmanager, eine Abfrage nach den Variablen Alter und Geschlecht auf den Datenbestand. Als minimale Abfragemenge wurde zehn gewählt. In der Kreuztabelle, die der Anwender als Ergebnis erhält, werden Merkmalskombinationen die zehnmal oder weniger vorkommen jedoch nicht angezeigt, sondern mit dem Wert Null beziffert.
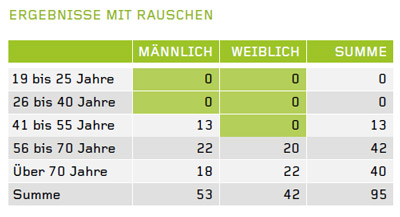
Hinzufügen von „Rauschen”: Hierbei werden die Analyseergebnisse geringfügig modifiziert. Dabei werden aufgrund eines Algorithmus, der eine definierte Wahrscheinlichkeitsverteilung abbildet, z. B. Laplace-Verteilung, die Merkmalsausprägungen einzelner Datensätze verändert oder weitere „unechte“ Datensätze hinzugefügt, welche in die Auswertung miteinbezogen werden.
Ergebnis und Verteilung werden dadurch nur geringfügig beeinträchtigt, es ist für den Anwender jedoch nicht mehr nachvollziehbar, welche der untersuchten Datensätze „echt“ sind und welche nicht. Natürlich gibt es bei diesem Vorgehen Einschränkungen, wenn die Genauigkeit der Daten unerlässlich ist.